Sie haben eine KI an Ihre Daten angeschlossen. Ein Chatfenster über dem Data Warehouse, ein Assistent im BI-Tool, oder jemand hat den Quartalsexport in ein Modell gekippt und gesagt: such mal das Interessante raus. Die Demo war beeindruckend. Eine Frage, an der ein Mensch einen Nachmittag gesessen hätte, war in zwanzig Sekunden beantwortet. Sauber formatiert, mit Diagramm und kurzer Zusammenfassung.
Dann hat jemand draufgeschaut, der die Zahlen kennt. Und die Zahl war falsch. Nicht wild daneben, sondern leicht daneben. Die KI hatte die falsche Tabelle gezählt. Oder "letztes Quartal" als Kalenderquartal gelesen, während der Vorstand das Geschäftsjahr meint. Das ist die gefährliche Sorte Fehler. Keine offensichtliche Halluzination, über die man lacht, sondern eine plausible, selbstbewusste, falsche Antwort. Gefährlich, weil die nächste Antwort plausibel, selbstbewusst und richtig sein kann, und Sie sehen den Unterschied nicht.
Die Frage landet auf Ihrem Tisch: Können wir dem Ding für eine Entscheidung trauen? Und der Reflex, Ihrer wie der des Anbieters, ist: nimm ein größeres Modell. Das schlauere kriegt das schon hin. Wird es nicht. Und warum es das nicht hinkriegt, ist der entscheidende Punkt.
Warum ein klügeres Modell das nicht löst
Ein modernes Modell ist wirklich gut darin, wie Geschäft im Allgemeinen funktioniert. Es erklärt Ihnen Kohortenbindung, argumentiert über eine GuV, schreibt eine Preisanalyse besser als die meisten, die Sie einstellen könnten. Was es nicht kann, und was keine Rechenleistung der Welt ihm gibt: wissen, wie genau Ihr Unternehmen funktioniert. Ihre Begriffe. Ihre Definitionen. Welcher Teil Ihrer Daten tragend ist und welcher Müll.
Nehmen Sie ein einfaches Beispiel. Das Wort "Umsatz". In der Buchhaltung ist das eine klar definierte Größe nach festen Regeln. Im Vertrieb meint dasselbe Wort oft die Pipeline, das, was reinkommen soll. Gleiches Wort, gleiches Unternehmen, zwei Bedeutungen. Oder "letztes Quartal": im Produktteam das Kalenderquartal, im Vertrieb das Geschäftsjahresquartal. Kein Modell löst das aus Intelligenz. Die Information steckt nicht in der Frage und nicht im Modell. Sie steckt in den Köpfen Ihrer Leute, die sagen würden: ach, du meinst das Geschäftsjahr. Und genau da kommt das Modell nicht hin.
Das Modell ist ein brillanter Analyst, der heute Morgen angefangen hat, Ihr Unternehmen noch nie gesehen hat und niemanden fragen kann. Ein klügerer Analyst mit demselben fehlenden Briefing macht dieselben Fehler, nur schneller.
Was fehlt, ist nicht IQ. Es ist die Karte. Wenn Sie googeln "KI kennt mein Unternehmen nicht", landen Sie bei genau dieser Lücke. Die Lösung heißt nicht: mehr Modell. Die Lösung heißt: der KI beibringen, was Ihre Daten bedeuten.
Die Bedeutungsschicht zwischen Modell und Daten
Zwischen Ihren rohen Daten und dem Modell gehört eine Übersetzungsschicht. Im Englischen heißt das semantic layer. Wir nennen es lieber die Bedeutungsschicht, weil das beschreibt, was es tut: Sie legt fest, was Ihre Daten meinen, bevor das Modell sie anfasst.
Denken Sie in drei Ebenen. Unten die rohen Daten, Tabellen, Spalten, die unaufgeräumte Wirklichkeit. Oben das Modell und der Mensch, der fragt. Dazwischen die Bedeutungsschicht: der Ort, an dem "Umsatz" an eine einzige Definition gebunden wird, an dem "letztes Quartal" aufgelöst wird, an dem festgehalten ist, welche Tabelle die echte ist und wie die Tabellen zusammenhängen. Das Modell argumentiert nie direkt über die rohen Tabellen. Es argumentiert über die Karte, und die Karte übersetzt seine Absicht in etwas, das man gefahrlos ausführen kann.
Genau das ist die Hälfte von KI-Bereitschaft, die fast alle überspringen. Die meisten sorgen zuerst dafür, dass der Agent Zugriff bekommt: Verbindungen, Zugangsdaten, die Werkzeuge, um überhaupt an die Daten heranzukommen. Notwendig, aber das ist nicht Verstehen. Ein Agent, der jede Tabelle erreicht und nicht weiß, welche zählt, ist nicht bereiter, er ist gefährlicher, weil er jetzt über all Ihre Daten falsch liegen kann statt nur über einen Teil.
Bei uns heißt diese Karte BrandOS. Das ist alles, was die KI über Ihr Unternehmen wissen muss, versioniert wie Code: Ihr Angebot, Ihre Sprache, Ihre Regeln, Ihre Quellen. Ohne diese Grundlage beantwortet jedes Team dieselbe Frage anders, und jeder Prompt erfindet das Unternehmen neu.
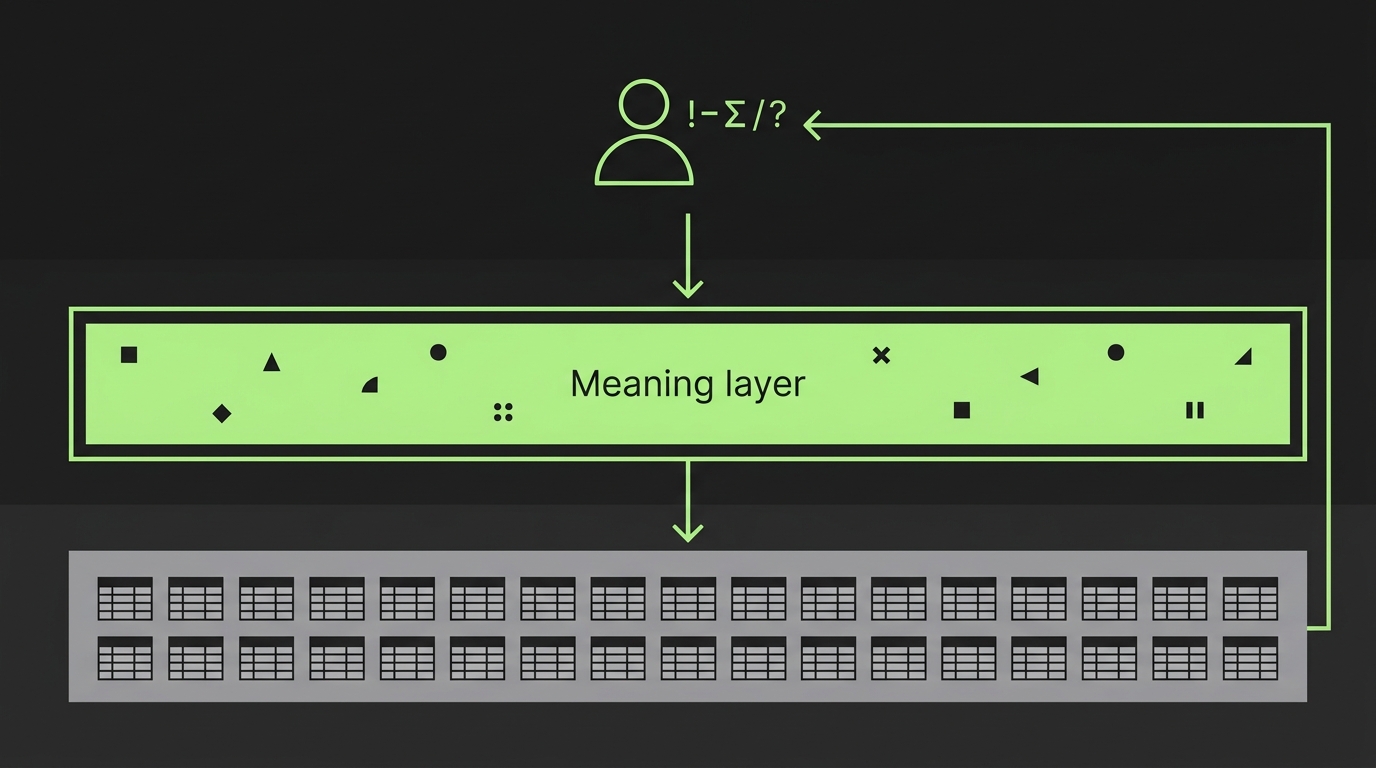
Die vier Aufgaben der Bedeutungsschicht
Eine Bedeutungsschicht verdient ihren Namen, wenn sie vier Dinge tut. Macht sie alle vier, wird ein fähiges Modell zu einem verlässlichen Analysten Ihres Geschäfts. Lassen Sie eine weg, kommen die selbstbewusst-falschen Antworten durch die Lücke zurück.
- Kuratieren: entscheiden, welche Daten wirklich zählen und wie die Teile zusammenpassen, damit das Modell nicht blind unter hundert Doppelgängern wählt.
- Bedeutung lokalisieren: die Erklärung neben das Feld legen, das sie beschreibt, nicht in ein fernes Dokument, damit der richtige Kontext das Modell genau dann erreicht, wenn es auf das Feld schaut.
- Berechtigungen erzwingen: die Schicht zur Grenze machen, nicht nur zum Wörterbuch, damit jeder nur die Daten sieht, die er sehen darf.
- Den Kreis schließen: die Karte als lebendig behandeln, weil Ihr Geschäft sich dauernd ändert und eine Karte, die letztes Quartal stimmte, dieses Quartal falsch ist, wenn niemand sie pflegt.
Kuratieren und Bedeutung lokalisieren
Eine KI sieht auf zehn sauberen Tabellen brillant aus. Echte Warehouses sehen anders aus. Da liegen zehntausende Datensätze, und unter ihnen hundert, die irgendwie nach "Umsatz" aussehen: der Export eines Teams, die Staging-Kopie eines anderen, drei "finale" Versionen. Ein Analyst weiß aus Erfahrung, dass man diese eine Umsatztabelle nimmt und die anderen neunundneunzig ignoriert. Das Modell weiß das nicht. Zeigen Sie ihm das Warehouse kalt, greift es sich eine Tabelle, vielleicht die, die drei Tage alt ist.
Kuratieren schafft diese Lotterie ab. Zwei Entscheidungen, einmal getroffen und aufgeschrieben: Welche Tabelle ist die kanonische für jeden Begriff, alle anderen sind nicht für Analyse. Und wie hängen sie zusammen, damit das Modell ein korrektes Bild baut statt doppelt zu zählen. Das ist die unglamouröseste und wirksamste Stunde, die Sie investieren. Jede spätere Antwort erbt sie.
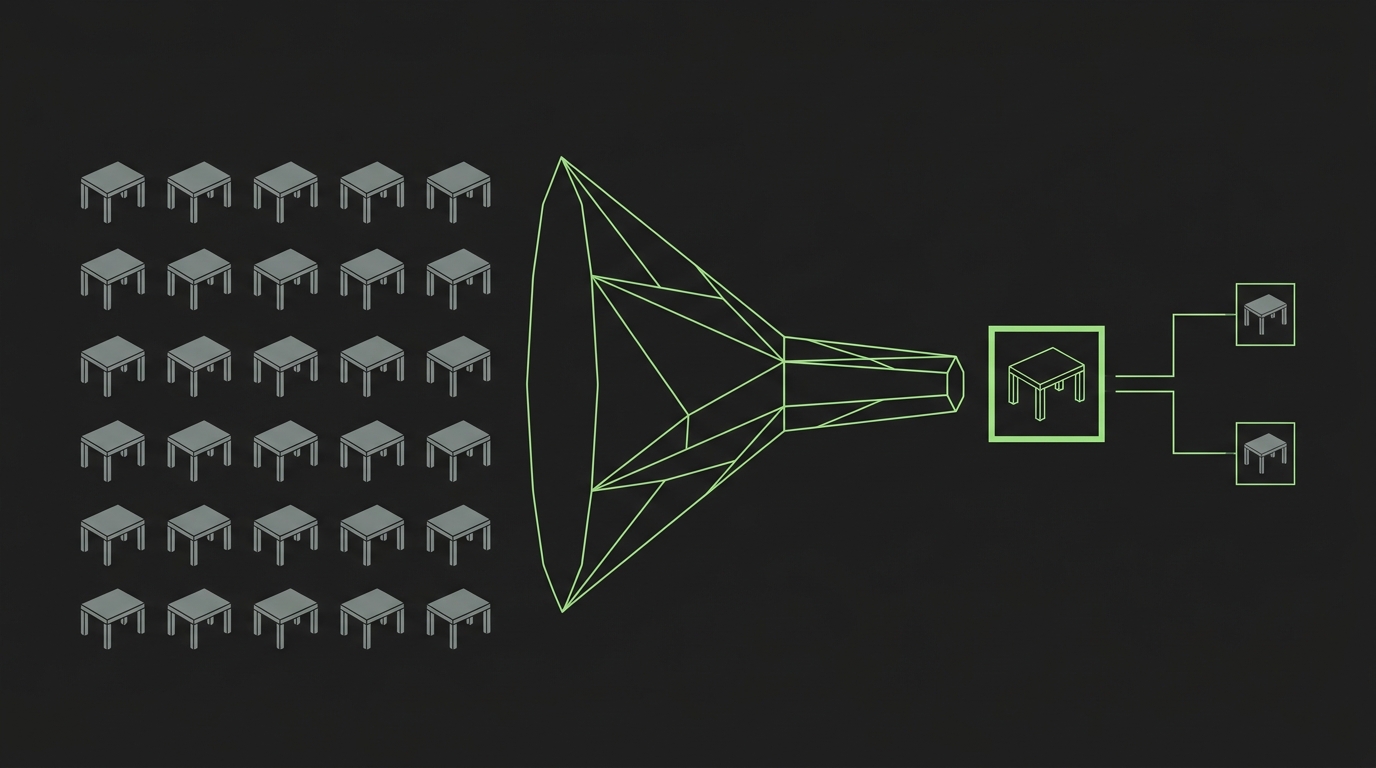
Dann muss das Modell wissen, was die Daten bedeuten, und wo Sie das hinschreiben, ist wichtiger, als die meisten glauben. Der Reflex ist, alles in ein Glossar zu packen, das "da drüben" liegt. Legen Sie die Erklärung stattdessen direkt neben das Feld, das sie beschreibt. Je näher der Kontext sitzt, desto verlässlicher erreicht er das Modell im richtigen Moment. Ein zentraler Ordner ist ein Kontext, den das Modell zu öffnen vergisst. Konkret hängen Sie ein paar Sorten Metadaten an jedes wichtige Feld.
- KI-Kontext: eine Notiz fürs Modell. Wie ist das Feld zu nutzen, womit wird es verwechselt, welches verwandte Feld ist vorzuziehen.
- Beispielabfragen: ein, zwei durchgespielte Fälle, an denen sich das Modell orientieren kann.
- Beispielwerte: eine Kostprobe dessen, was wirklich im Feld steht. Sieht das Modell, dass ein Regionsfeld DACH, EMEA, NAM enthält, und jemand fragt nach "Deutschland", weiß es, nach DACH zu suchen statt nach dem wörtlichen Begriff. Menschen tippen, wie Menschen reden; Daten sind gespeichert, wie Daten gespeichert sind. Beispielwerte überbrücken das, samt Tippfehler.
Berechtigungen erzwingen und die Karte aktuell halten
Eine Karte, die dem Modell alles erklärt, aber nicht weiß, wer fragt, ist ein Leck mit Ansage. Ein Dashboard zeigt die Ansichten, die Sie absichtlich gebaut haben. Ein Fragefenster zeigt alles, was der Agent erreichen kann, jedem, der clever genug ist, die Frage zu stellen. "Was ist das höchste Gehalt in der Firma?" ist ein normaler Satz. Ob er beantwortet wird, sollte allein davon abhängen, wer ihn getippt hat. Diese Entscheidung darf nicht im guten Willen des Modells liegen, ein Modell lässt sich überreden. Sie muss in der Schicht liegen, angewendet auf jede Abfrage, bevor sie läuft.
Für ein Unternehmen im DACH-Raum läuft hier die Compliance-Linie: DSGVO, rollenbasierter Zugriff, die Daten, die Betriebsrat oder Kunden hinter einer Mauer erwarten. Deshalb ist die Berechtigungsgrenze nicht verhandelbar. Eine Bedeutungsschicht ohne sie ist keine kleinere Version des Projekts, sondern ein anderes und unsicheres.
Bleibt die vierte Aufgabe, und sie entscheidet, ob die Schicht in sechs Monaten noch stimmt. Definitionen ändern sich dauernd: eine neue Produktlinie, ein umbenanntes Segment, eine Kennzahl, die der Vorstand in einer Sitzung neu definiert hat, in der Sie nicht waren. Eine einmal gezeichnete und liegengelassene Karte driftet leise aus der Wahrheit, und die falschen Antworten kriechen zurück, jetzt schwerer zu erkennen, weil die Karte mal richtig war.
Die Lösung ist ein Feedback-Loop. Jede Frage ist ein Hinweis. Eine Frage, an der der Agent scheitert, zeigt auf eine fehlende Definition. Ein Begriff, den Nutzer tippen und den die Schicht nicht kennt, zeigt auf ein fehlendes Synonym. Wichtig: ein Mensch bleibt in der Schleife. Der Agent schlägt eine Verbesserung vor, ein Mensch, dem die Definition gehört, genehmigt sie. So verbessert sich die Karte unter Ihrer Kontrolle, statt im Dunkeln zu mutieren. Und genau hier, bei der Frage wer die Karte aktuell hält, scheitern die meisten KI-Projekte leise.
Ein Test, und der nächste Schritt
Wenn Sie wissen wollen, ob Ihre KI Ihr Unternehmen kennt, stellen Sie ihr eine Frage, deren Antwort von einer internen Definition abhängt. Etwa: Wie war unser Umsatz letztes Quartal? Dann prüfen Sie nicht nur die Zahl, sondern fragen nach. Welche Tabelle hast du genommen? Welches Quartal meinst du? Wessen Definition von Umsatz? Kann die KI das nicht sauber beantworten, fehlt nicht das Modell, es fehlt die Karte.
Und eine Karte können Sie bauen. Wer die Bedeutung einmal neben die Daten legt, zahlt einmal und erntet bei jeder Antwort danach. Wer es lässt und jedem Prompt das Raten überlässt, zahlt jedes Mal wieder, mit Antworten, denen er nicht trauen kann.
Das ist auch der Grund für unsere Nein-Sätze. Wir zeigen mit einem Agenten nicht auf einen ungeregelten Datensumpf und nennen das bereit. Wir liefern keine Bedeutungsschicht ohne ihre Berechtigungsgrenze. Und Sie bringen Ihre eigenen Zugänge mit, wir sitzen nie zwischen Ihnen und dem Modell. Ein Fundament, das hält, ist mehr wert als eine Demo, die blendet.
Wenn Sie ein Fundament wollen, auf dem Ihre KI über genau Ihr Unternehmen verlässlich wird, ist AI Academy der Weg.
Häufige Fragen
- Warum gibt meine KI falsche Antworten über mein eigenes Unternehmen?
- Weil das Modell zwar Wirtschaft im Allgemeinen versteht, aber Ihre Begriffe, Definitionen und Datenstruktur nicht kennt. Es weiß nicht, welche von hundert Umsatztabellen die richtige ist oder ob "letztes Quartal" das Kalender- oder das Geschäftsjahr meint. Diese Information steckt in Ihrem Unternehmen, nicht im Modell.
- Löst ein größeres oder neueres KI-Modell das Problem?
- Nein. Ein klügeres Modell mit demselben fehlenden Wissen über Ihr Unternehmen macht dieselben Fehler, nur schneller und überzeugender formuliert. Was fehlt, ist keine Intelligenz, sondern eine Bedeutungsschicht zwischen Modell und Daten, die dem Modell sagt, was Ihre Daten bedeuten.
- Was ist eine Bedeutungsschicht und was hat sie mit BrandOS zu tun?
- Die Bedeutungsschicht ist die Übersetzungsebene zwischen Ihren rohen Daten und dem Modell. Sie bindet Begriffe an eine Definition, legt fest, welche Tabelle zählt, und erzwingt, wer was sehen darf. Bei uns ist das BrandOS: alles, was die KI über Ihr Unternehmen wissen muss, versioniert wie Code.
- Wie sorge ich dafür, dass die KI meine eigenen Unternehmensdaten richtig versteht?
- In vier Schritten: die Daten kuratieren, die wirklich zählen; die Bedeutung jedes Feldes direkt daneben dokumentieren; eine Berechtigungsgrenze einziehen; und einen Feedback-Loop aufsetzen, der die Karte aktuell hält. Genau diese vier Schritte bauen wir im AI-Readiness-Fundament auf, das danach Ihnen gehört.